 DeTransformer Overview
DeTransformer Overview
Abstract
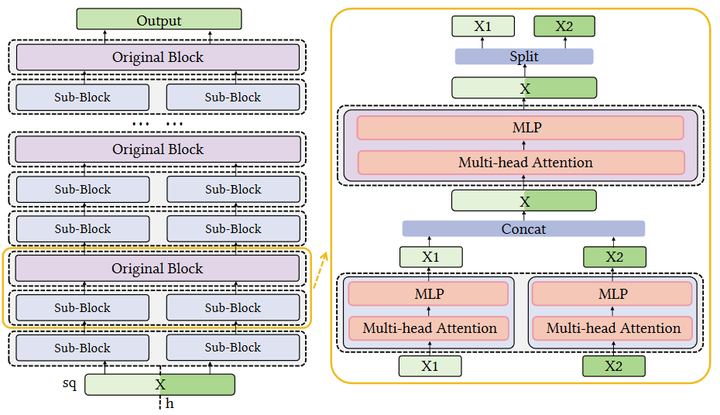
Transformer models have shown significant success in a wide range of tasks. Meanwhile, massive resources required by its inference prevent scenarios with resource-constrained devices from in-situ deployment, leaving a high threshold of integrating its advances. Observing that these scenarios, e.g. smart home of edge computing, are usually comprise a rich set of trusted devices with untapped resources, it is promising to distribute Transformer inference onto multiple devices. However, due to the tightlycoupled feature of Transformer model, existing model parallelism approaches necessitate frequent communication to resolve data dependencies, making them unacceptable for distributed inference, especially under weak interconnect of edge scenarios. In this paper, we propose DeTransformer, a communicationefficient distributed in-situ Transformer inference system for edge scenarios. DeTransformer is based on a novel block parallelism approach, with the key idea of restructuring the original Transformer layer with a single block to the decoupled layer with multiple sub-blocks and exploit model parallelism between sub-blocks. Next, DeTransformer contains an adaptive placement approach to automatically select the optimal placement strategy by striking a trade-off among communication capability, computing power and memory budget. Experimental results show that DeTransformer can reduce distributed inference latency by up to 2.81× compared to the SOTA approach on 4 devices, while effectively maintaining task accuracy and a consistent model size.
Shengyuan Ye
Ph.D. student at SMCLab
He is a Ph.D. student at School of Computer Science and Engineering, Sun Yat-sen University. His research interests include Resource-efficient AI Systems and Applications with Mobile AI.
Xu Chen
Professor and Assistant Dean, Sun Yat-sen University
Director, Institute of Advanced Networking & Computing Systems
Xu Chen is a Full Professor with Sun Yat-sen University, Director of Institute of Advanced Networking and Computing Systems (IANCS), and the Vice Director of National Engineering Research Laboratory of Digital Homes. His research interest includes edge computing and cloud computing, federated learning, cloud-native intelligent robots, distributed artificial intelligence, intelligent big data analysis, and computing power network.
Jiangsu Du
PostDoc, Sun Yat-sen University
He obtained Ph.D. degree at School of Computer Science and Engineering, Sun Yat-sen University. He is now a PostDoc at the Sun Yat-sen University, working on High Performance Computing, and Distributed Artificial Intelligence System.